CLIP, LLaVA, and the Brain - What the brain can teach us about visual processing
How do recent artificial neural networks, like the CLIP (Radford et al. 2021) and LLaVA (Liu et al. 2023) transformer networks, compare to the brain? Is there similarity between the attention in these networks to that in the brain? In this article I look at these transformer architectures with an eye on the similarity and differences with the mammalian brain and visual system.
I come to the conclusion that the processing that vision transformers, CLIP, and LLaVA perform is analogous to a type of computation called pre-attentive visual processing. This processing is done in the initial feedforward visual responses to a stimulus before any recurrence. Although a lot can be accomplished in a feedforward way, studies have shown that feedforward pre-attentive processing in the brain does have difficulty with:
- Distinguishing the identity or characteristics of similar types of objects, especially when objects are close together or cluttered or the objects are unnatural or artificial (VanRullen 2007).
- More complex tasks such as counting or maze or curve tracing tasks.
- Perceiving objects that are more difficult to see, such as where it is difficult to perceive the boundaries of the objects.
In contrast to the feed-forward only processing, one of the things that really stands out with the brain the richness in the interaction of areas, which I will discuss in more details in the next section.
Bidirectional Activity in the Brain
In most current deep learning architectures, activity is propagated in a single direction, for example, an image might be given as input to a network and then propagated from layer to layer until you get to a classification as the output.
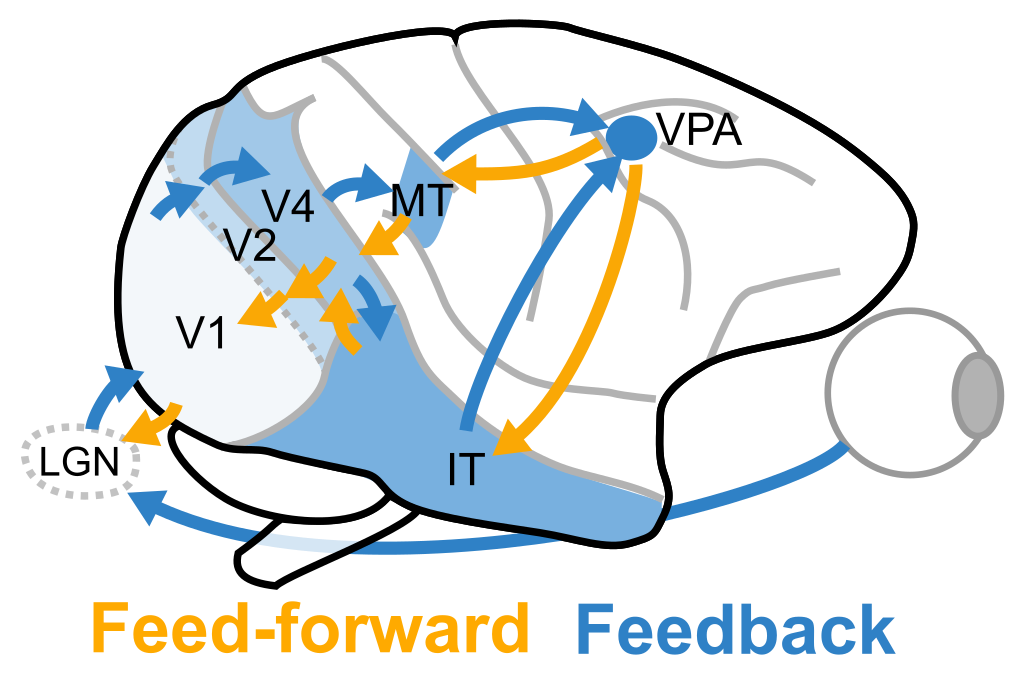
The brain is much more interesting than these feedforward models. In the visual system, a stimulus will propagate from lower to higher level areas in a feedforward-like fashion, but then the higher level areas will also influence the lower level areas as shown in Figure 1.
Some of this feedback is the conscious top-down attention that allows us to allocate more resources to objects and features of interest and allows us disambiguate stimuli that is either complex or ambiguous. Another part of this feedback is automatic and allows higher level areas to infuse the lower level areas with information that could not be known in just the feedforward manner.
The conscious top-down attention is thought to support consciousness of visual stimuli. Without conscious access to lower level areas that encode borders and edges, we wouldn’t have as spatially precise perception of borders. Tasks such as mentally tracing a curve or solving a maze would become impossible.
One example of the automatic unconscious feedback is border-ownership which is seen in about half of the orientation-selective neurons in visual area V2 (Zhou, Friedman, and von der Heydt 2000; Williford and von der Heydt 2013). These neurons will encode local information in about 40 ms and, as early as 10 ms after this initial response, will start to incorporate global context to resolve occlusions - holding the information needed to know which object are creating borders by occluding their backgrounds.
Another example of this unconscious feedback was shown in Poort et al. (2012) using the images like that in Figure 2. In the Macaque early visual cortex V1, neurons will tend to initially (within 50-75 ms of stimulus presentation) encode only the local features within their receptive fields (e.g. green square). However, after around 75 ms, they will receive feedback from the higher level areas and they will tend to have a higher response when that texture belongs to a figure, such as this texture defined figure above. This happens even when attention is drawn away from the figure, however if the monkey is paying attention to the figure the neurons will tend to respond even more.

One way to look at this bidirectional interaction is that at any given time, each neuron greedily uses all available predictive signals. Even higher level areas can be informative.
Transformers
With all the talk about attention with the introduction of transformers (Vaswani et al. 2017) and with the ability to generate sentences one word at a time, you might be led to believe that transformers have recurrence. However, there is no “state” that is kept between the steps of the transformer, except for the previous output. So at best the recurrence is very limited and there is no bidirectionality that is ubiquitous in the brain. Transformers do allow for multi-headed attention, which could be interpreted as being able to attend to multiple things simultaneously. In the original paper, the transformer used 8 attention heads. Image transformers can be seen as analogous to pre-attentive feedforward processing with some modifications, like with the multiple attention heads.
CLIP
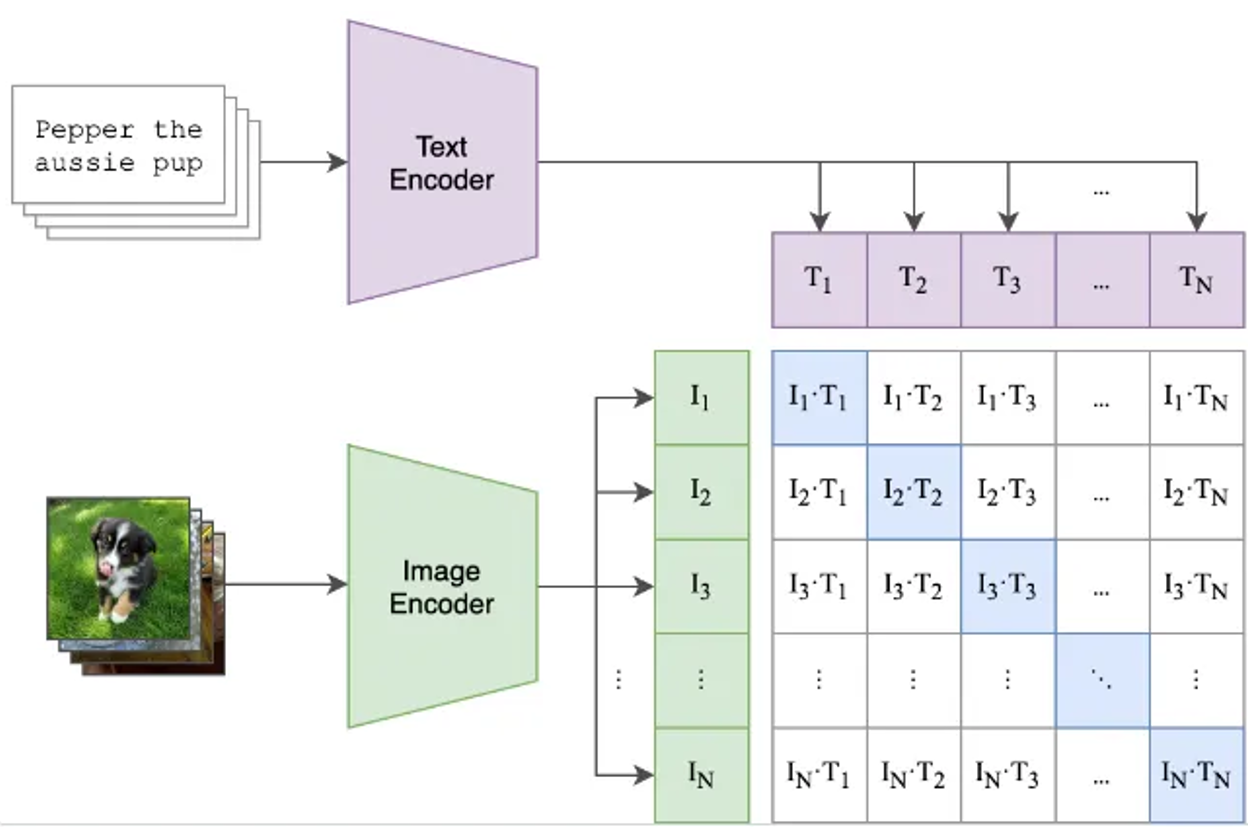
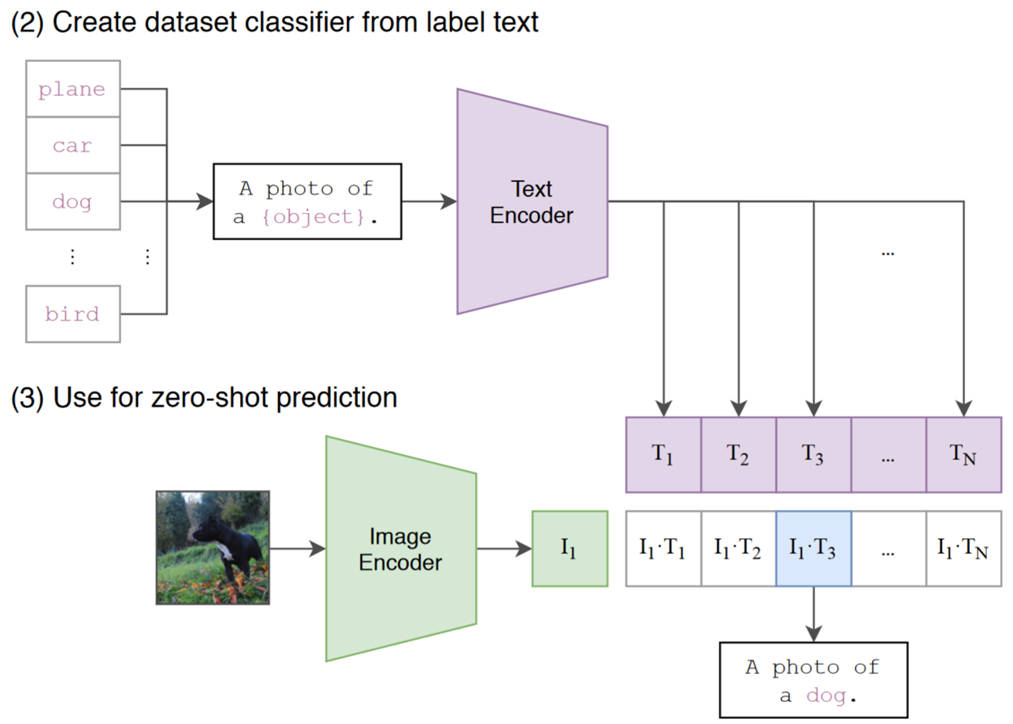
CLIP was introduced by OpenAI in the Radford et al. (2021) paper “Learning Transferable Visual Models from Natural Language Supervision”. The idea behind CLIP is pretty simple and is shown in Figure 3. It takes a bunch of image and caption pairs from the Internet, feeds the image to an image encoder or and the text to a text encoder. It then uses a loss that brings the encoding of the image and the encoding of the text closer together when they are in the same pair, otherwise the loss increases the distance of the encodings. This is what CLIP gives you: the ability to compare the similarity between text and images. One way this can be used is for zero-shot classification, as shown in Figure 4. CLIP does not, by itself, generate text descriptions from images.
The image encoder and text encoder are independent, meaning that there is no way for task-driven modulation to influence the image encoding. This means that the image encoder has to encode everything that could be potentially relevant to the task. Typically the resolution of the input image is pretty small, which helps prevent the computation and memory requirements from exploding.
LLaVA
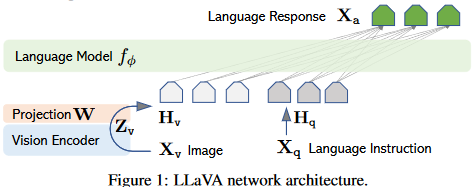
Large Language and Vision Assistant (LLaVA) (Liu et al. 2023) is a large language and vision architecture that extends and builds onto CLIP to add the ability to describe and answer questions about images. This type of architecture is interesting to me because it can attempt tasks that are similar to those used in Neuroscience and Psychology.
LLaVA takes the vision transformer model ViT-L/14 that is trained by CLIP for image encoding Figure 5. To convert the encodings into tokens, the first paper uses a single linear projection matrix \(W\) for this transformation. The tokens calculated from the images \(H_v\) and the tokens from the text instructions \(H_q\) are provided as input. LLaVA can then generate the language response \(X_a\) one token at a time, each time appending the response so far as the input to the next iteration.
I won’t go into the details of how LLaVA is trained, but it is interesting how they use ChatGPT to expand the caption (\(\mathrm X_c\) in Figure 5) to form instructions (\(\mathrm H_q\)) and responses (used to train \(\mathrm X_a\)) about an image and the use of bounding box information.
In version 1.5 of LLaVA (Liu et al. 2024), some of the improvements they made include:
- The linear projection matrix \(\mathrm W\) is replaced with a multilayer perceptron
- The image resolution is increased by using an image encoder that takes images of size 336x336 pixels and split the images into grids that are encoded separately.
Task driven attention in the brain is able to dynamically allocate resources to the object, location, or features of interest, which can allow processing of information that could otherwise be overwhelmed by clutter or other objects. In LLaVA, the image encoder is independent of the text instructions, so to be successful it needs to make sure any potentially useful information is stored in the image tokens (\(\mathrm H_v\)).
Conclusion
Since LLaVA and CLIP lack bidirectional processing, the processing that they do is limited. This is especially true for image processing, since image processing is done independent of the text instructions. Most convolutional neural networks also shares these limitations. This leads me to my conjecture:
Conjecture: Most convolutional, vision transformer, and multimodal transformer networks is restricted to something pre-attentive feedforward visual processing.
This is not necessarily a criticism as much as an insight that can be informative. Feedforward processing can do a lot and is fast. However, it is not as dynamic as to what resources can be used to be used, which can lead to informational bottlenecks in cluttered scenes and is unable to encode enough information for complex tasks without an explosion of the size of the encodings.
There are some networks that are not limited to pre-attentive feedforward networks, but currently most of the architectures lag behind those of transformers. These include, long-short term memory models (LSTMs) and, more recently, the Mamba architecture which has several benefits over transformers (Gu and Dao 2024). Extended LSTMs (Beck et al. 2024; Alkin et al. 2024) have been proposed that help make up some of the ground between transformers and LSTMs.
References
NEUROAI
neuroscience deep-learning transformers CLIP LLaVA attention bidirectionality recurrence